As most of us know, our “cloud” of applications isn’t always perfect.
Sometimes a service may go down, whether or maintenance or because of an issue. Perhaps an API changes, giving you different information - or even an error. So what does a Flowgrammer do?
In this module we’ll explore proactive techniques for Exception Handling, learn more about Error Notifications and Review to help you manage - and potentially avoid - common pitfalls.
Course Material
As most of us know, our “cloud” of applications isn’t always perfect.
Sometimes a service may go down, whether or maintenance or because of an issue. Perhaps an API changes, giving you different information - or even an error. So what does a Flowgrammer do?
In this module we’ll explore proactive techniques for Exception Handling, learn more about Error Notifications and Review to help you manage - and potentially avoid - common pitfalls.
Exception and Error Handling
Exception Handling - Defined
Let’s begin this section by defining Exception Handling. Many of you may already be aware of what this is, but it’s always good to go back to the basics …
- An exception occurs when an unexpected event happens that may require special treatment
- Exception Handling is how we respond to exceptions when a Flow runs
Let’s consider some examples …
Missing Information
Creating new record sometimes fails due to missing information. An example if this could be a missing required field (such as an assignee - an owner for an Opportunity or Account). Additionally, you might get into solutions where you realize Flows are erroring because you have to create a record, but the API requires certain components.
Imagine if you’re working with Salesforce. Perhaps data was coming from another location was missing - in some circumstances - so Flows may keep failing.
Record Type Mismatch
Only certain types of records should be processed through Flow. Remember, if you’re working with one record type (like a date) and your system expects another, this may result in mismatch errors.
System Maintenance / Outages
If you know that a system may be under maintenance at certain times OR you know that a system might have an unexpected outage … you can proactively manage for maintenance you know is about to happen!
Exception Handling Tools
We have a number of tools for your Exception Handling “toolbox”. Let’s take some time to discuss and work through some common examples of the kinds of approaches that you would take to address common exception handling issues …
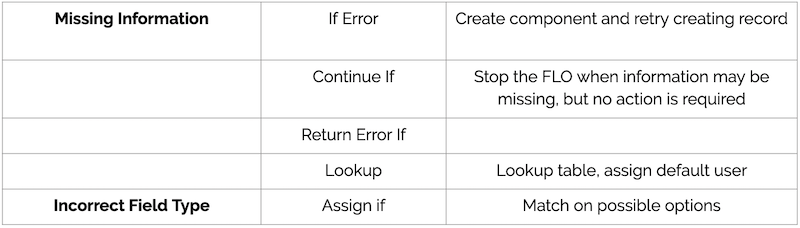
Missing Information
- If Error
- The If Error card allows you to create your component and then retry creating records
- This is very handy lot of use cases around error handling
- Continue If
- For basic cases where no action is required, you can always leverage a “Continue If”
- Continue If will halt a Flow based on a conditional test, but does not throw an error
- Good in cases where you don’t want to error out if information is not presented and isn’t needed
- Lookup
- Super-handy for many scenarios, such as mapping to one thing in a different thing
- You can quickly create lookups to translate between values
Incorrect Field Type
Here you may want to make sure you catch information that’s not of the correct type …
- Assign If is great for proactively “catching” things that you know have the potential for failing
Return Error If
Throwing an error is helpful if certain requirements are not being checked.
You may, however, want to use Return Error If instead of Continue if. Both will stop a Flow based on logic. But if you use Return Error If you’ll get more feedback with a specific error message.
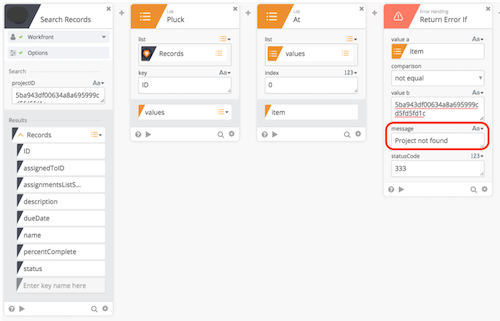
Gotcha: If you use Continue If - it will show up in execution history as “success”
Return Error If will show up as execution history as an error instead of “success”. This is a little bit of a gotcha where people will ask, “why didn’t my Flow run all the way through”
Scenario: Continue If Gives Success - Even with Failures
Let’s consider the execution history that accompanies a Continue If card (Demoing here):
- Create a Continue If card
- Set it to 1 = 2 (never will be the case)
- If I run this, it will be successful in execution history
- Run the Flow
- We checked if 1=2 … It’ll never happen!
- It was a success but nothing else in the Flow happened!!!!!
- This may not be good because there might be times though that you want to stop the Flow earlier, but need to see differently in execution history
Resolution: Add “Return Error If” card.
The Return Error If card will allow you to define/customize your own error such that reviewers will quickly see and understand the problem within Execution History. Knowing what you might need to surface in execution history and how you might need to remediate things efficiently.
Exception Handling - Proactive
System Offline for Maintenance
At times applications are taken offline for scheduled maintenance. If the offline application is the receiving system, have executions wait for a specified period of time, queuing up executions up to the wait point. Cards that are good for this: Wait Until, Wait For
Maintenance periods may have much larger impact to the Flows. When they occur you’ll get a ton of errors when that system is offline.
You can PROACTIVELY use cards such as:
Wait Until
- Lets you put in exact date/time
Wait For
- Maybe you know it’s a 5-10 hour maintenance period.
- “Wait For” can also be really handy if you’re dealing with Race Conditions
If you wanted one of the systems to continue to allow for executions - but temporarily hold and not allow to pass through until the system maintenance window has completed (like if you know it’ll be a 5 hour maintenance period).
Exception Handling - More Proactivity!
Only certain types of records should be processed through Flow.
Check record output for certain criteria (e.g. external reference ID, updates by certain account, no missing values) via Continue If or Return Error If cards.
As an example … Maybe you have a bunch of different Flows that are having to create records - and things are being synced back and forth - but many at one time.
For example you may be doing a search for a record before you make an attempt to create it. And if you find nothing, perhaps you put a Wait For and give 1-2 minutes just in case there’s another Flow doing that action - then make another attempt (we’ve seen people do this). It’s a pretty handy card for many different scenarios like that.
Exception Handling - Proactive Retry
Errors due to system time-outs, API rate limits or known edge cases can often be resolved proactively.
Within the Error Handling section of a card, you can retry up to 3 times with 1-5 minute wait period.
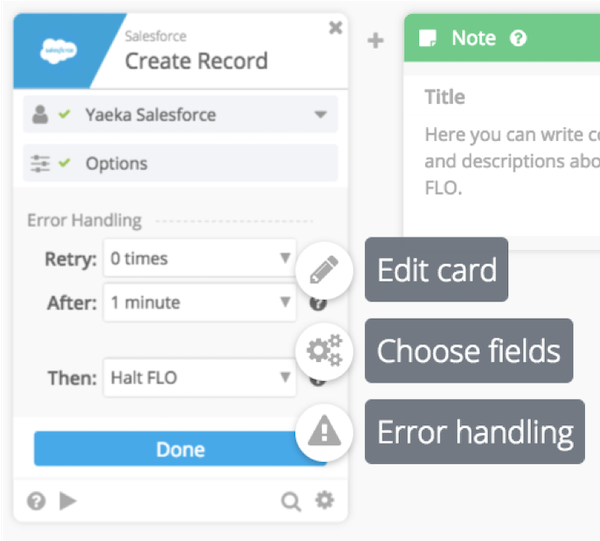
There are some systems you’ll want to use more often than not. In particular, when you’re working with really slow response times.
Sharepoint, for example, doesn’t have a lot of rate limit issues, however, sometimes it’s really slow. This is particularly true if you have a really large instance.
- In such cases, we’ll recommend automatically retrying three (3) times with a 3-minute wait between each.
Other times, once in production if you realize that there’s timeouts or rate limit issues - you’ll want to turn on.
NOTE: There will be a Green Indicator at the bottom of a card if you have Error Handling turned on.
Error Notifications
Many types of errors require human review before it can be resolved, such as:
- Authentication failures
- Incorrect Flow syntax
Note that there are lots of errors that you can’t proactively manage but you need to sent information to someone to fix things. If human intervention is required, consider setting up an error notification system.
Error Notifications - Email and Instant Messages
Flow-based Handling: Email and Instant Message
Build a notification system to deliver messages to resolution team
Examples:
- Email: Create record action fails because system configuration is required -> send email/IM to system administrator
- Instant Message: If /Error -> send slack message to admin
In these situations, you need to decide how people are notofice and who’s doing what. Slack / Email are commonly used. Sometimes have both for transparency.
Partner Messaging:
You probably want to port all messages into your “core org” and triage however you like. You want to do this because you don’t want to put personal messages into a customers org.
Then if you have a Slack connected to a customer org - you want to make sure that’s part of the built-out solution.
Error Notifications - In-App Notifications
If you’re managing multiple environments you should also consider the value of using in-app notifications.
In-App Notifications
In these cases you should return errors to the originating system. E.g. If System A is creating/updating item in System B, but B fails to create/update item, log note in system A
Example: If / Error -> log note/comment in originating system so user sees in the record that Flow failed because of an incorrect input. They can resolve and try again.
Reminder About Notifications
Our platform offers two email services to keep you informed with what is happening with your Flows:
Daily Email Summary
- Azuqua daily email summary is the best way to keep an eye on Flows and make sure no new errors are surfacing.
Immediate Error Notification Email
- Customers may now opt-in to receiving emails whenever a Flow gets an error.
- This allows customers to know when there may be issues with their Flows without needing to be in Azuqua at the time. These emails send at most once an hour.
Daily summary is really handy in the beginning when you want to monitor your Flows a little more closely.
Error Review
You want to be thoughtful with design so it’s easy to review errors. You also want to be sure that you have options and some tips/tricks for things you might try if you’re trying to troubleshoot.
Examples:
- Create temp error log: If / Error -> create row in table
- Log error details in an Azuqua table or another spreadsheet based application (e.g. Google Sheets, Excel).
- This information is most helpful to see patterns or trends over time.
- At minimum, it’s recommended to include in the log report the log time, execution ID and error message
- Custom Error Messages: Intentionally throw an error
- Return Error and Return Error If -> custom error message surfaced in execution history for easy review
Temp Error Log Notes
You can set tables up and leverage them for logging errors. It’s helpful to put (at least temporarily) all the data into a table so you have a flat table space to see everything collectively.
Tables - ultimately - are not meant for large volumes of data. They have limits, but if used temporarily they can be effective. To get around limits, you can export into CSV, Excel, etc.
Also, if you can’t figure out what’s going on it’s well worth your time to gather a day’s worth of executions into a table and review.
Custom Error Messages
You can use If Error - custom error messages to display really important messages so you can quickly find that in execution history.
Important Reminder about Errors
New Flowgrammers may be confused by what they see in execution history. Remember, if a CHILD Flow errors you will see the same error in the child Flow as well as parent except if async or ignore errors card are being used. So … make sure you design your flos respectively.
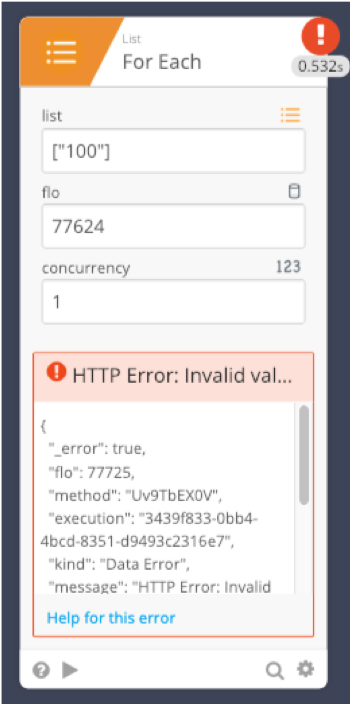
Remediation
If an error cannot be resolved proactively with built in exception handling or by a front end user, the following can resolve errors (see below):
| Error | Remediation |
|---|---|
| Authentication/Configuration Errors | Log into Azuqua and reauthorize account |
| Type conversion errors | Correct conversion logic and/or input/output field types |
| Incorrect Flow syntax | Correct Flow syntax |
| Request Timeout | Manual execution history retry from failure point |
| API rate limits | Manual execution history retry from failure point |
| Expected errors/Known edge cases | Manual retry from beginning of the Flow |
Manual Retry - From Point of Failure
If a Flow fails you can Replay that Flow by doing the following:
- Click replay from the execution history
- This will attempt from the failure point using the original inputs.
- If Successful - the Flow will resume through the rest of the Flow.
Note: If the Flow failure was due to an incorrect Flow setup and you update the Flow, the error will not be resolved by replay. The replay will run through the original Flow setup.
A great way to remediate - just hit the button (replay) and the Flow will try to repeat itself. When you hit this and it remediates -it will become a success and you’ll no longer see the error. This will use all the same identical inputs/outputs and it will start from the failure point.
You might also have cases where enough time has passed and maybe you do need to refresh, do new searches, make sure nothing else has changed and not try the replay. If you added a lot of new cards, retry will not try to use these new cards. Instead, it will try to replicate what was there.
Manual Retry from Beginning of the Flow
If you want to retry from the beginning of the Flow, copy all of the output values from the execution history you want to retry. Test the Flow by manually entering the copied values and hit “Test”.
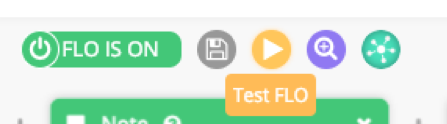
If you do need to run again from the start (not from failure) just use the “test card” option. This option allows you to manually enter all the inputs into this card - then you know this newly run Flow will adhere to all these new edits.
Summary
As you can see there are a tremendous number of options for working with Errors. Above all, being proactive will help you avoid issues that could halt or block your Flows from running and provide valuable information on how to troubleshoot!