In this module we cover Troubleshooting - particularly focused upon the “Post-Live” state. What happens when things (applications) change and/or your Flows aren’t working correctly? Read more to find out!
Course Material
In this module we cover Troubleshooting - particularly focused upon the “Post-Live” state. What happens when things (applications) change and/or your Flows aren’t working correctly? Read more to find out!
Overview
You’ve designed and launched a Flow (or series of Flows) and it runs along nicely … until it doesn’t!
In our cloud-based ecosystem of applications, things change. When this happens, and one of your Flows “breaks” what steps should you take to troubleshoot things and get them back in working order?
Causes of Flow Problems
A variety of things could cause a Flow to “break”. Some of the most common that we’ll discuss here are changes related to or issues with:
- Application API / Authentication
- User-Specific Errors
- Connectivity, and other factors

Let’s review some examples!
Potential Flow Problems
The first kinds of issues that you could encounter are generally related to your vendor’s application … commonly the API service itself.

With respect to the applications that you use (consume), the API itself could cause your problems. For instance, tokens you’ve used to set up your connection to an application API may have changed or even expired. Your password may have changed or expired as well.
Occasionally there will be authorization issues with your cards and you may have to re-authorize your connection to the service. This is done by clicking on the tab that has the human outline and following the outlined steps. If this doesn’t solve your problem, you may have to create a new authorization configuration with the same account.
“Under the Hood” perhaps there have been schema changes or configuration changes to the API itself. This is less likely for managed connectors (e.g. those that Azuqua creates), but certainly possible (more so in cases where you are not using a predefined event or action).
Additionally, a Flow may fail to run if your application vendor is having an outage or maintenance period.
Best Practice: Monitor Your Flows
First things first … a key Best Practice is to regularly monitor your Flows!
For example, you may have set up:
- Daily summary email
- Immediate Notifications
- Or Custom email notifications
We recommend a Distrubition List / Alias over individual email for notifications.
Flow Monitoring Tip #1: Team Email Alias
What happens If you go on vacation and are out of office and don’t get an error notification?
The Problem: Errors may get missed The Solution: Set up a “team@domain.com” alias to ensure that someone sees / addresses any issues
Also, we recommend that you don’t use INDIVIDUAL accounts (use an alias / team email that’s non-expiring).
Flow Monitoring Tip #2: Check App Activity Streams
As you’re leveraging Flows to Automate your processes, realize that information will be updated via whatever account you authorize.
Perhaps you’re seeing strange issues:
The Problem: How do I know if my Flow is causing an issue? The Solution: If possible - use a Non-Expiring Integration Account (not a personal one) so you can quickly identify records that are produced by a Flow
Best Practice: Check Application Status
Flows are highly dependent upon the connectors to your applications. As you go to troubleshoot - you should check that all connections are working correctly. Your Flow should give you some indication if there are issues with the applications in question.
Many applications provide a server status page so you can quickly gather information about an outage or other service issue. Here are some examples:
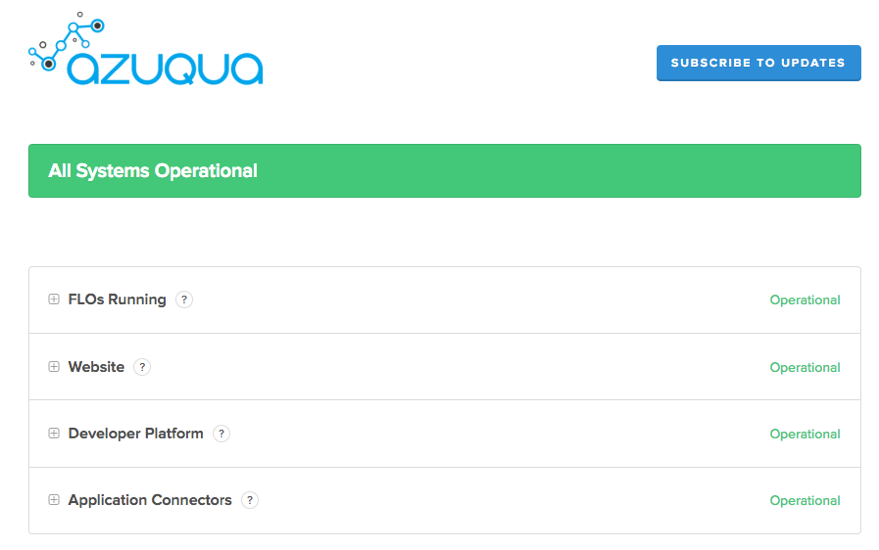
In short - checking your apps first can avoid a support ticket and help you set expectations!
Best Practice: Implement Error Handling
One more best practice to consider is to make sure that your Flows are built to proactively handle errors.
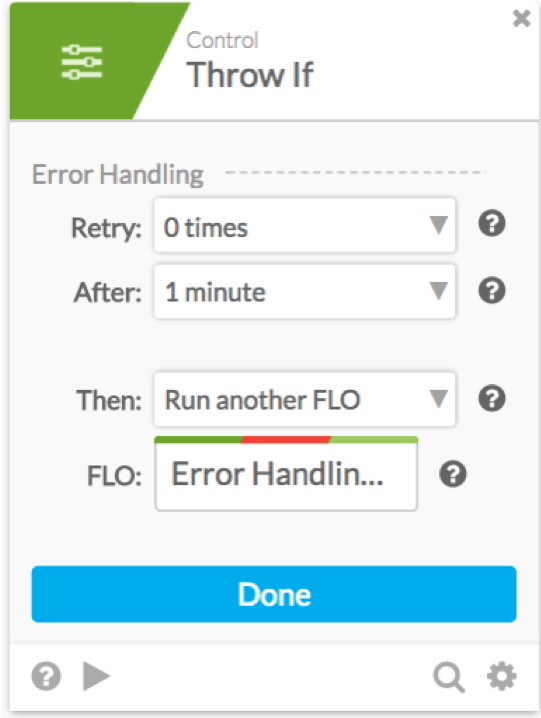
We won’t go into the details of Error Handling within this module, but you could use things like the If Error or Throw If cards. While these may take some time to think through, if you can’t always guarantee that things will always work correctly, they’re extremely valuable to have in your toolkit.
Flow Problems - User-Specific errors
Your Application Providers may not always the culprit if and when a Flow “breaks”.
If your Flow isn’t working correctly, what kinds of things should you be looking for?
Let’s talk through some examples …
- Errors in your Flow
- Make sure you’re on the lookout for things like - Missing fields, incorrect field types (between cards), and even simple logic errors.
- Changes to the underlying data
- Your applications themselves may experience changes. For example, perhaps you’re using a Google Sheet for a Flow
- What if someone (maybe even you) change a column header or other information. It may cause a Flow to act strangely or even throw an error
- Example: Using a Google Sheet, but changed column headers that a Flow is expecting
- Schema changes to a database
- Similar to changing fields, column headers, etc. You may be dependent on a database. Changes to that may affect your Flow. Could even be permission issue or more.
Best Practices:
- Overall, it’s up to you (and potentially your team) to KNOW YOUR DATA.
- Best Practice: Know your data sources and proactive work to avoid or accommodate changes that could affect your Flows
- In our rapidly changing world - things change - so be aware of your environment so you don’t have any surprises!
Flow Problems - Connectivity and More
And finally there’s the “catch-all” of Connectivity and Other Problems that are harder to categorize …
These could be:
- Service Outage
- Again, for our service you can check any status updates here: https://status.azuqua.com
- General Network/connectivity Issues
And on a lesser note - while it isn’t common, changes to a Card within Designer can happen. As with other applications, Azuqua itself could be affected by an outage or maintenance so we encourage you to always keep Server Status and other updates.
- Note: For most services you can subscribe to a mailing list to any updates! We definitely recommend doing this so that you’re proactive.
Specific Error Messages
How are errors are presented in Flows when you’re troubleshooting?
In many cases, a service will send back detained information as to why an error happened.
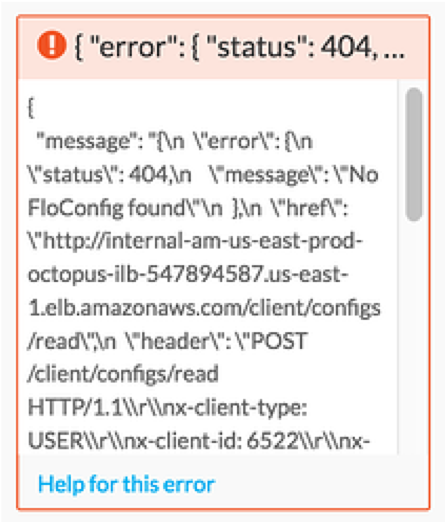
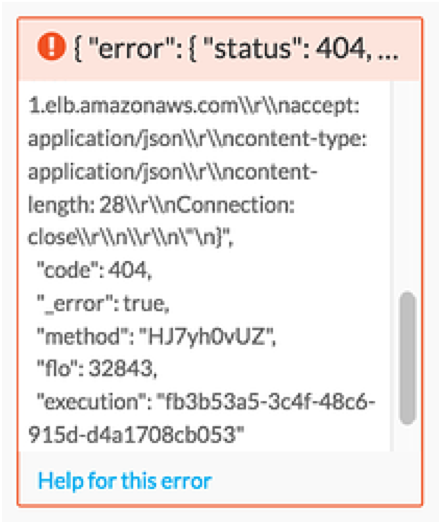
This information will sometimes include a value that can help you triage why the error happened in the first place. Helpful information can be found following keys such as “message”: (where the text found after “message”: is the message that is returned from the external service) or buried in the text following the “error”: key.
Other Error Messages
What happens if I don’t have this kind of detail with the error messages?
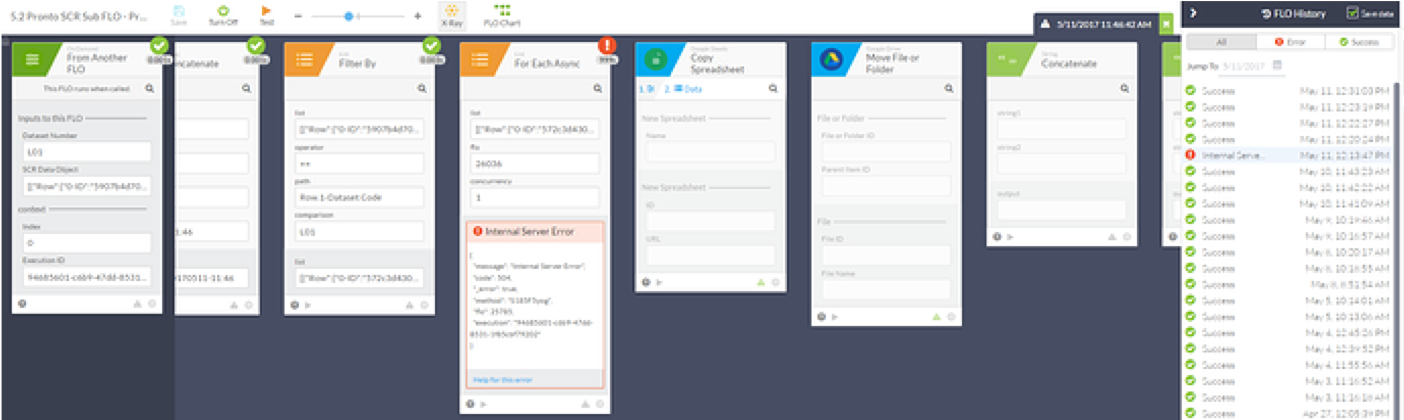
For example, you may get an error (like a 500 error) which may not include many helpful bits of information. They do, however, inform you as to generally where something is going wrong and may give you or those helping you to resolve the errors.
An example may look something like this:
Troubleshooting Overview / Decision Tree
While we can’t encompass each and every example, we have assembled a model for how you can approach your problems in a decision tree:
http://bit.ly/flo-troubleshooting
There’s also a guide in our community which you may find helpful at this URL:
http://bit.ly/resolving-errors
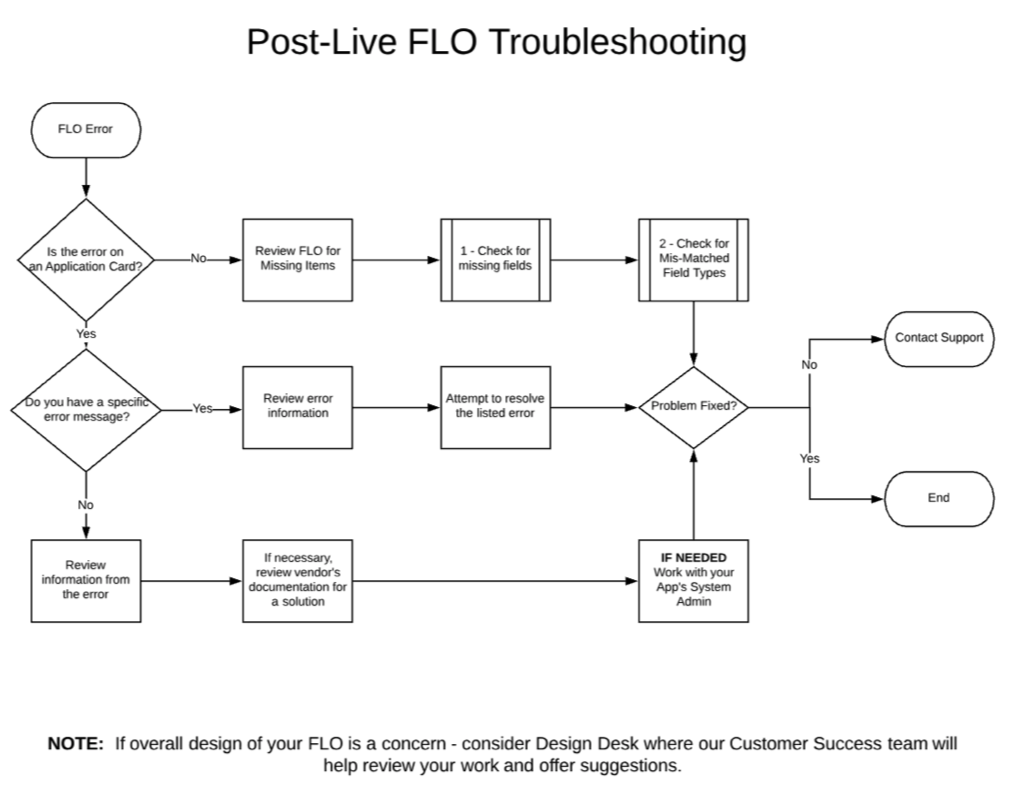
For this section we recommend watching the above video with more detail!
Contacting Support
Being able to troubleshoot your own issues is massively important, but sometimes you may have to contact support.
If and when you do work with support, there are two key things that we recommend that you include:
- The Entire Error Message
- If there’s an error on a card, copy the entire error message and send this to Support. This will include the error code, message, etc.
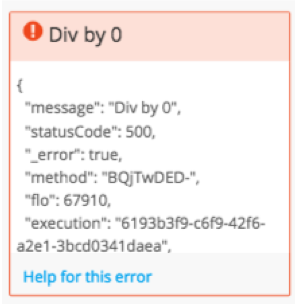
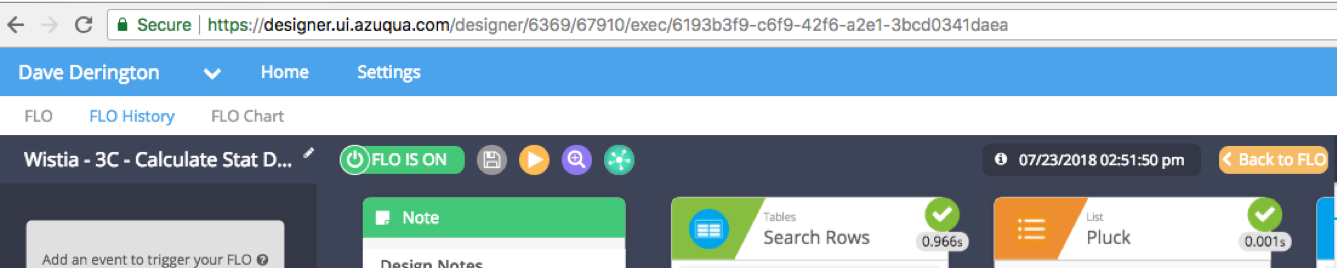
- The Execution history URL
- Copy and send the entire url which will include the Flow ID, Org ID and execution history ID.
Also, if the error isn’t on a specific card or in a specific execution history then you should provide your Org ID, a description of what you see happening that doesn’t look correct, and description of what you are expecting to have happened.
And remember, if you don’t know your Org ID, it is typically in your header after /org OR can be found under Settings >> Organization
Error Remediation
So to summarize this …
- Retry
- Retry is a systemic option for which our system uses to remediate errors - automatically
- This helps in particular with connections that may be prone to timeouts, etc.
- In other words, if you have a connection - sometimes like SFDC (API limit) or others - that you know may not be 100% reliable, the RETRY feature (on a card) will help try up to three times automatically.
- Replay
- Replay is different
- This comes into play if retry fails you
- This resumes the card from where the failure happened with the data that was used at that time.
- This is only good for cases that aren’t time-sensitive or otherwise dependent on the specific time. REPLAY may not always be available from the side panel.
- Error Handling
- Particularly if you’ve experienced a set error before, you can also set things up to “catch” this kind of error
- Notification
- And above all, make sure you’re receiving notifications when things error
- We’d also recommend sending this to a team alias (in case you’re not available!)
Note that we will offer another module that goes much deeper into Troubleshooting and Error Remediation in the future.
Summary
Surely there are many more ways to troubleshoot your Flows when things go wrong, but we’ve listed some ideas that should help streamline your process or even help you proactively avoid issues!